A geração aumentada de recuperação é frequentemente posicionada como a Solução preferida para otimizar LLMS. Mas, apesar da integração do RAG em sistemas Agentic, o LLMS ainda pode apresentar reivindicações não suportadas ou contraditórias ao conteúdo recuperado.
Imagine um analista de negócios em uma empresa de logística usando um assistente interno de IA alimentado pela RAG para interagir com os relatórios financeiros. Quando o analista pergunta, “Qual é o nosso desempenho no segundo trimestre?”o assistente responde: “Nossa receita do segundo trimestre diminuiu 15% em comparação ao primeiro trimestre devido a interrupções da cadeia de suprimentos após o bloqueio do canal de Suez”.
Enquanto o sistema recuperou corretamente o relatório financeiro, observando uma queda de receita de 15%, fabricou uma justificativa atribuindo o declínio ao bloqueio do canal de Suez – uma explicação não presente no material de origem.
A recuperação de documentos não garante precisão, então o próprio RAG deve ser otimizado. Isso significa ajustar a pesquisa para retornar os resultados certos, incluindo menos ruído e alinhar a resposta do LLM com o contexto recuperado.
É por isso que, neste artigo, discutiremos como os sistemas RAG ainda podem alucinar e fornecer uma estrutura para avaliar os aplicativos de RAG usando a estrutura Ragas. Por fim, apresentaremos como implementar avaliações de RAG no N8N.
Quatro tipos de alucinações de trapos
As alucinações têm uma definição ligeiramente diferente no contexto de RAG. Usamos o termo para indicar que uma resposta não é suportada ou alinhada com o contexto recuperado. É considerado uma alucinação quando o LLM não gera conteúdo com base nos dados textuais fornecidos a ele como parte do processo de recuperação de RAG, mas gera conteúdo com base em seu conhecimento pré-treinado.
Vectara, os criadores dos modelos de avaliação do HHEMdê o seguinte exemplo: se o contexto recuperado estados “A capital da França é Berlim”e as saídas LLM “A capital da França é Paris”então a resposta do LLM é alucinada, apesar de estar correta.
Podemos categorizar alucinações específicas para rag em quatro categorias, conforme descrito no artigo intitulado Ragtruth:
- Conflito evidente: para quando o conteúdo generativo apresenta contração direta ou oposição às informações fornecidas. Esses conflitos são facilmente verificáveis sem contexto extenso, geralmente envolvendo erros factuais claros, nomes com erros de ortografia, números incorretos etc.
- Conflito sutil: Pois quando o conteúdo generativo apresenta uma partida ou divergência das informações fornecidas, alterando o significado contextual pretendido. Esses conflitos geralmente envolvem a substituição de termos que carregam diferentes implicações ou gravidade, exigindo uma compreensão mais profunda de suas aplicações contextuais.
- Introdução evidente de informações infundadas: Para quando o conteúdo gerado inclui informações não comprovadas nas informações fornecidas. Envolve a criação de detalhes hipotéticos, fabricados ou alucinatórios sem evidências ou apoio.
- Introdução sutil de informações infundadas: É quando o conteúdo gerado se estende além das informações fornecidas incorporando detalhes, insights ou sentimentos inferidos. Essas informações adicionais carecem de verificabilidade e podem incluir suposições subjetivas ou normas comumente observadas, em vez de fatos explícitos.
A estrutura de avaliação de pano de dois pilares
Uma boa implementação de pano pode validar duas coisas:
- Certificando -se de que Rag recupere as informações corretas. Esta é a relevância do documento de RAG.
- Garantir que as respostas LLM sejam consistentes com o contexto recuperado via RAG. Isso é a base do trapo
A maioria das ferramentas disponíveis hoje usa o Biblioteca Ragasque fornece um conjunto de funções de avaliação específicas do RAG. Utilizamos as avaliações disponíveis na biblioteca Ragas nas descrições abaixo.
Documento de RAG Relevância: Recuperando o contexto certo
O Recall de contexto A avaliação mede quantos dos documentos relevantes foram recuperados com sucesso. Maior recall significa que menos documentos relevantes foram deixados de fora. Precisão do contexto é uma métrica que mede a proporção de pedaços relevantes nos contextos recuperados. O cálculo do recall de contexto sempre requer uma referência para comparar.
A recall e a precisão podem ser calculadas usando um juiz LLM ou usando cálculos determinísticos.
Recall de contexto baseado em LLM é calculado usando três variáveis – a entrada do usuário, a referência e os contextos recuperados. Para estimar o recall de contexto a partir da referência, a referência é dividida em reivindicações, cada reclamação na resposta de referência é analisada para determinar se ela pode ser atribuída ao contexto recuperado ou não.
Precisão de contexto baseada em LLM é usado para estimar se um contexto recuperado é relevante ou não com um LLM comparar cada um dos contextos ou pedaços recuperados presentes em contextos recuperados com a resposta.
Não baseado em llmo Recall de contexto e precisão Compare contextos ou pedaços recuperados com os contextos de referência. Essas métricas usam medidas como similaridade semântica, razão de similaridade de Levenshtein e métricas de comparação de cordas para determinar se um contexto recuperado é relevante ou não.
Fotão de trapos: avaliação de respostas contra o contexto recuperado
Fidelidade determina o quão uma resposta é factualmente consistente com o contexto recuperado. Uma resposta é considerada fiel se todas as suas reivindicações puderem ser apoiadas pelo contexto recuperado. HHEM-2.1-OPEN de Vectara é um modelo de classificador de código aberto que é treinado para detectar alucinações do texto gerado por LLM. Pode ser usado para verificar reivindicações com o contexto fornecido para determinar se pode ser inferido do contexto.
Relevância da resposta Mede o quão relevante é uma resposta para a entrada do usuário. Uma resposta é considerada relevante se abordar direta e adequadamente a pergunta original. Essa métrica se concentra em quão bem a resposta corresponde à intenção da pergunta, sem avaliar a precisão factual. Ele penaliza as respostas incompletas ou incluem detalhes desnecessários.
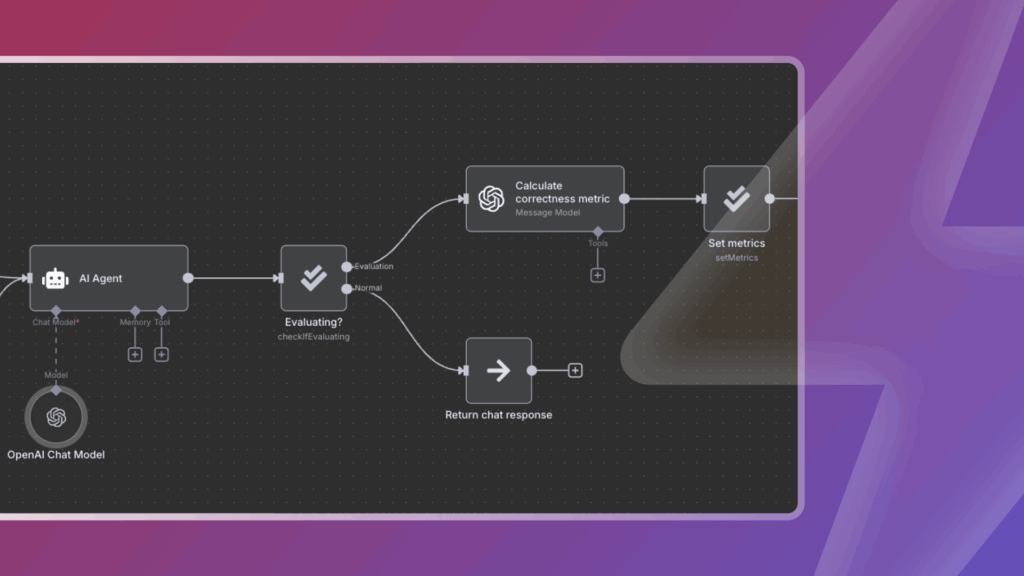
Avaliações de pano em N8N
Você pode avaliar o desempenho do RAG em N8N sem bibliotecas ou chamadas externas. As avaliações disponíveis nativamente incluem a relevância do documento do RAG e a aterramento de respostas. Eles calculam se os documentos recuperados são relevantes para a pergunta e se a resposta está fundamentada nos documentos recuperados. As avaliações de RAG são executadas contra um conjunto de dados de teste e os resultados podem ser comparados entre as execuções para ver como as métricas mudam e perfuram as razões para essas mudanças.
O Avalie a precisão da resposta ao traje com o fluxo de trabalho OpenAi O modelo usa a relevância da resposta baseada em LLM para avaliar se a resposta é baseada nos documentos recuperados. Uma pontuação alta indica a aderência e o alinhamento LLM, enquanto uma pontuação baixa pode sinalizar um prompt inadequado ou modelar alucinação.
O Relevância do documento de pano O Workflow usa uma recuperação de contexto baseada em LLM para calcular uma pontuação de recuperação para cada entrada e determinar se o fluxo de trabalho está funcionando bem ou não.
Para entender mais sobre a avaliação no N8N, confira o Apresentando avaliações para a postagem do blog de fluxos de trabalho da IAe nosso Documentação técnica no nó de avaliação.









